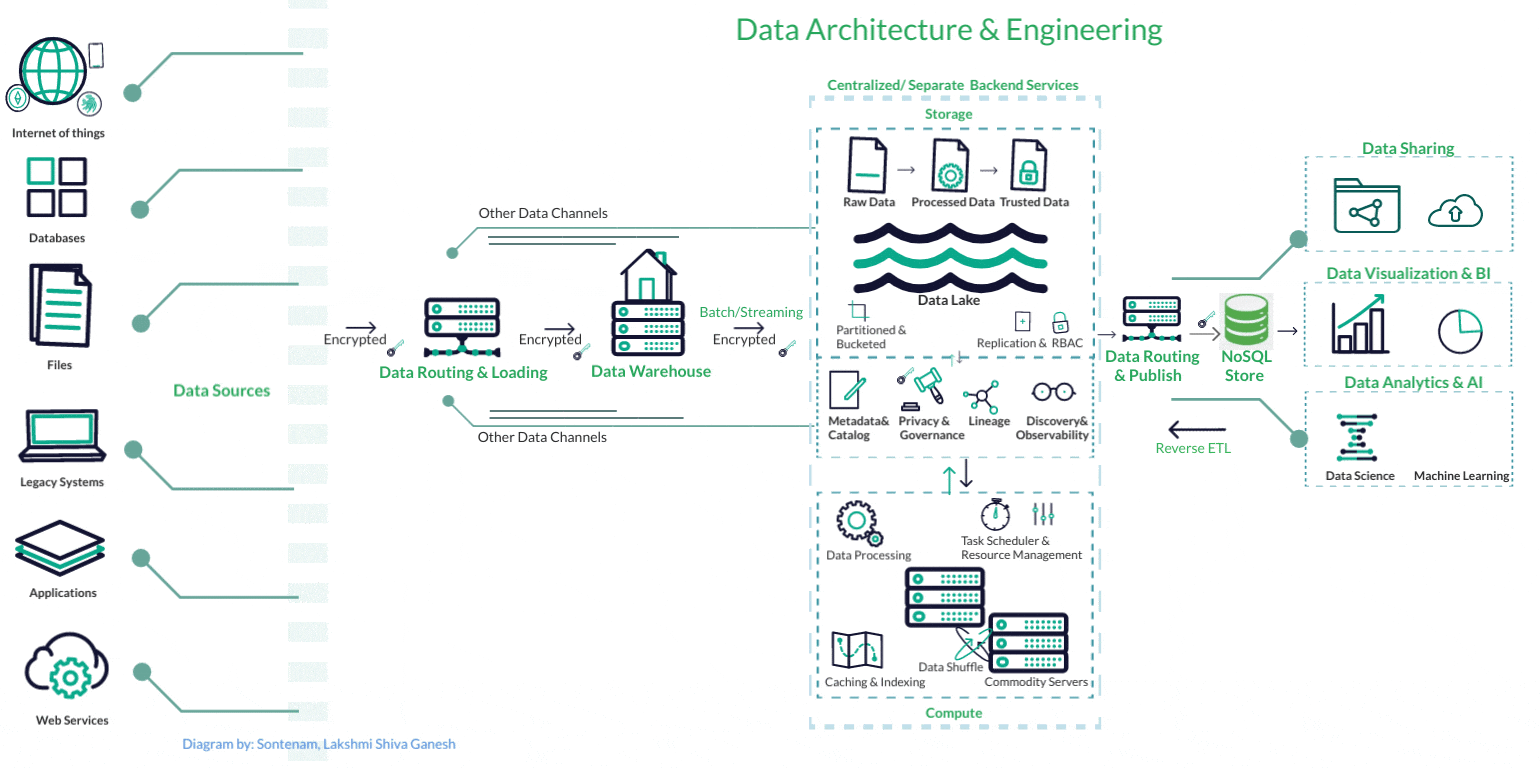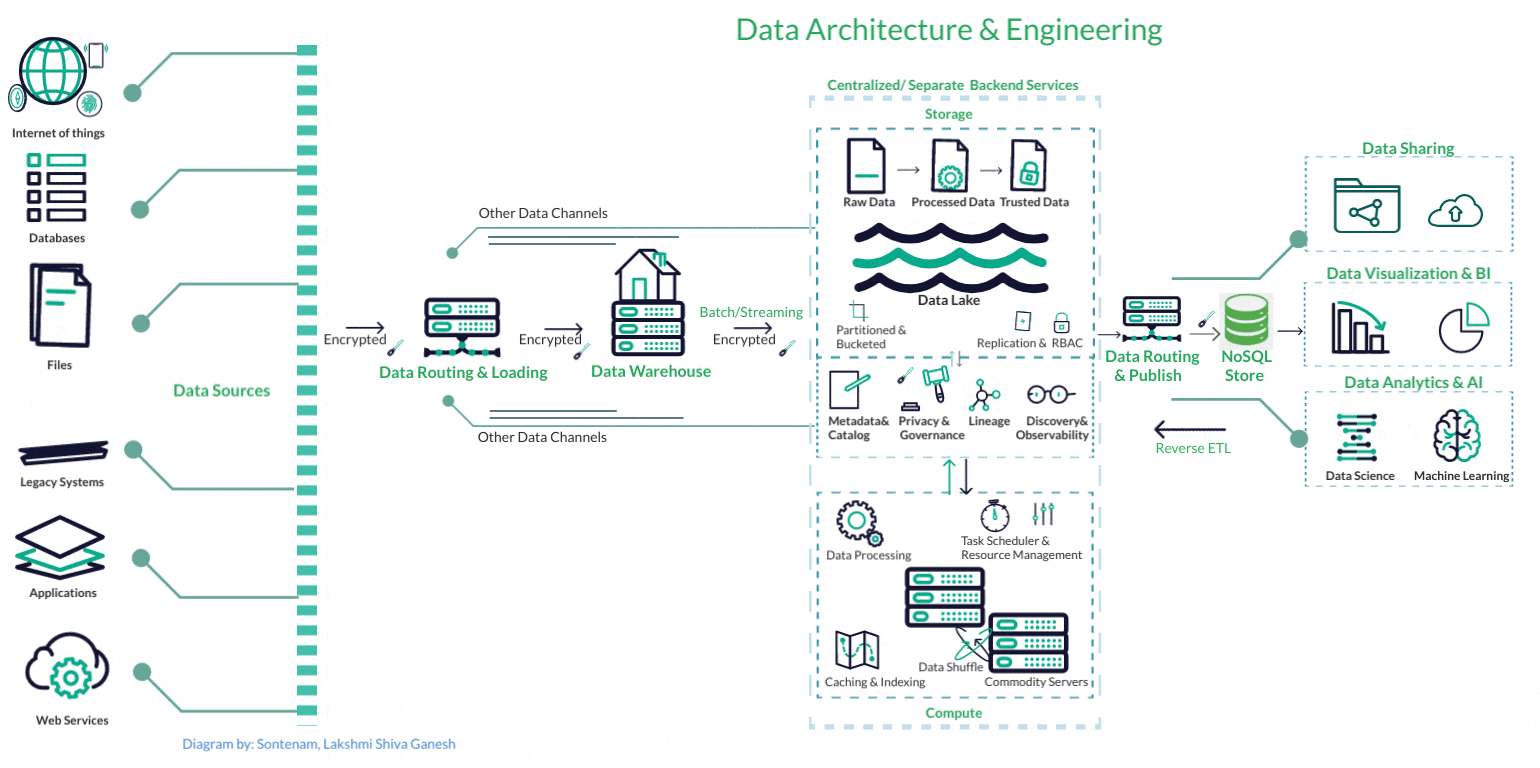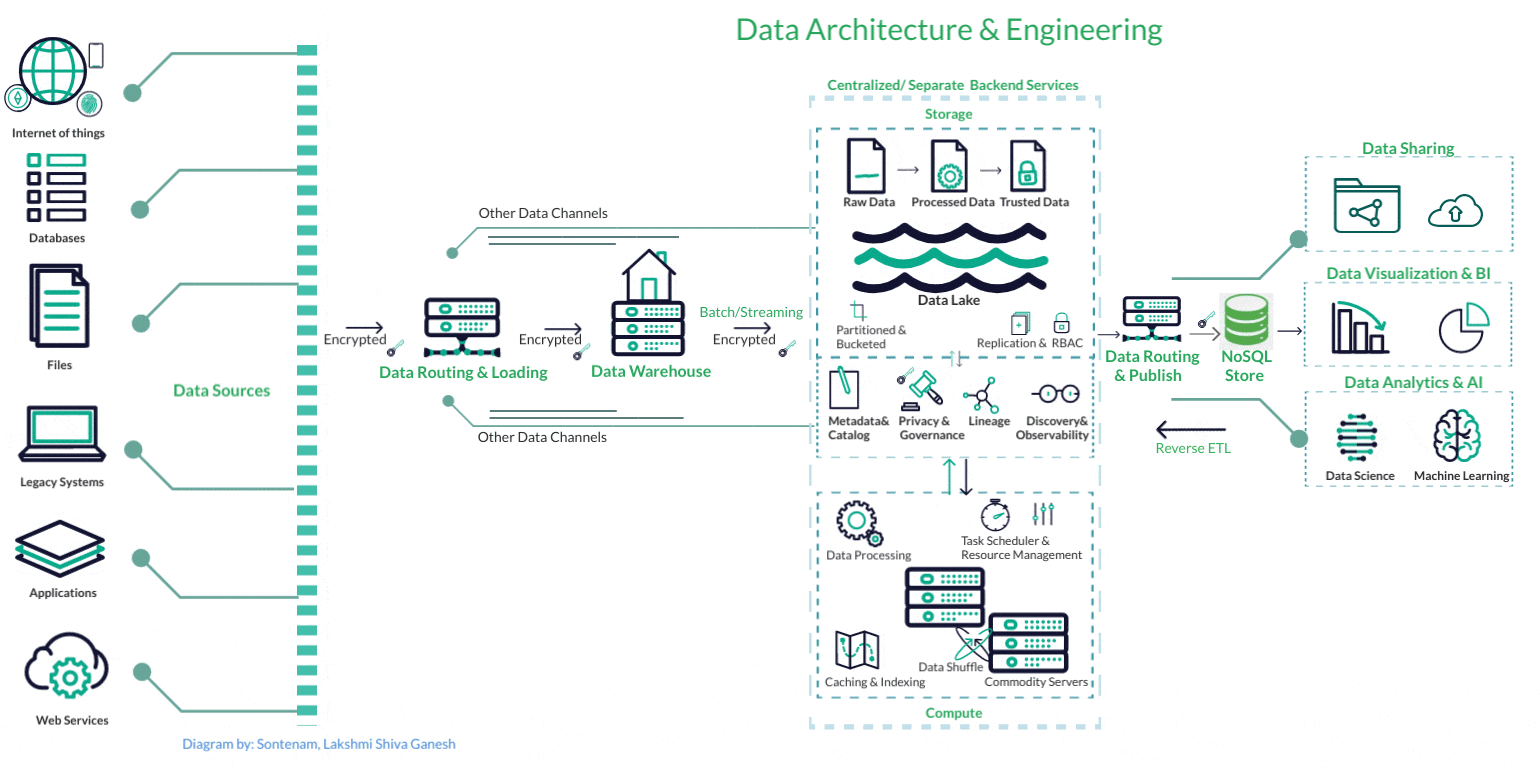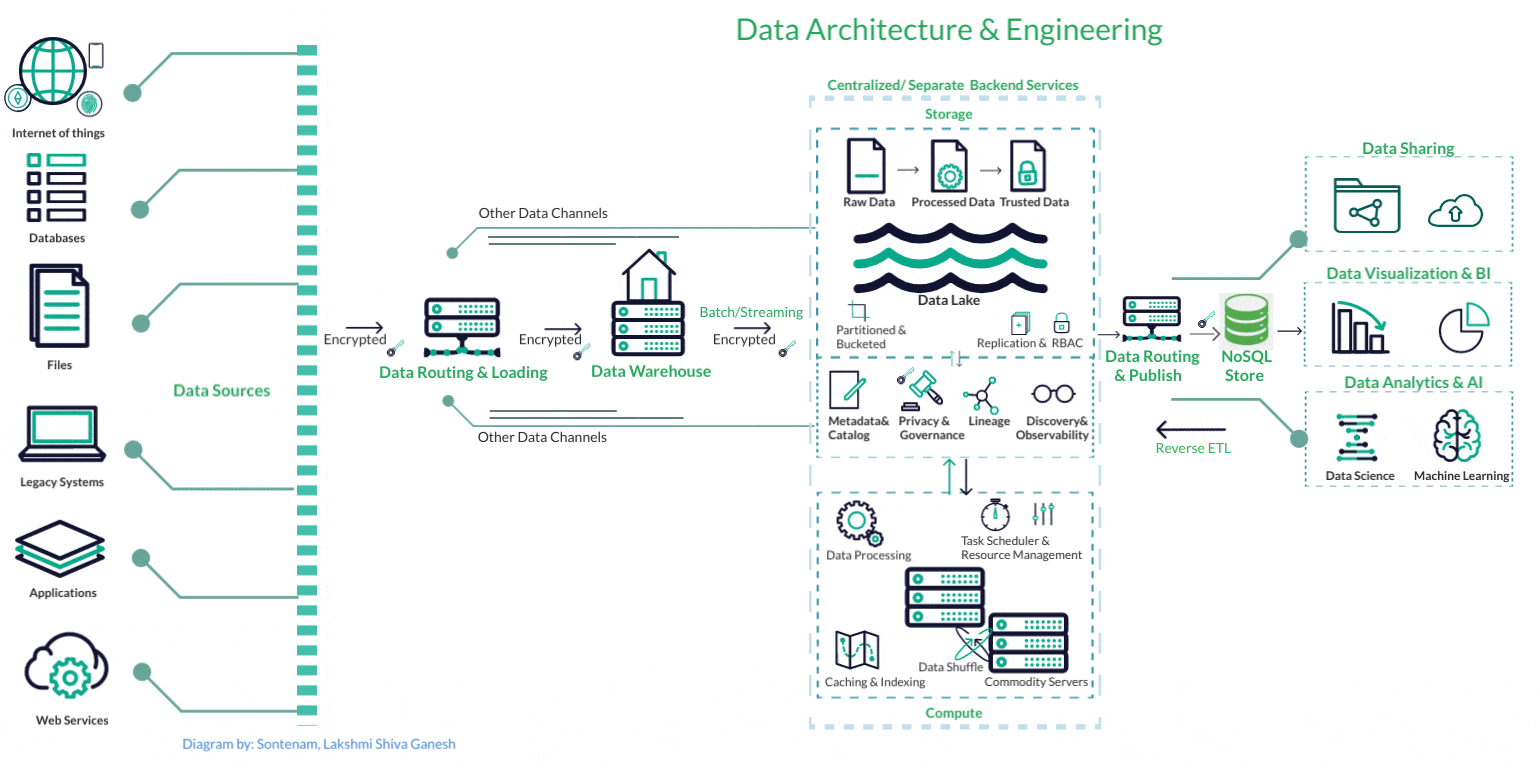
Data Engineering
Data ServicesFrom building scalable data warehouses and data lakes to designing efficient ETL (Extract, Transform, Load) processes, we ensure that data flows seamlessly across systems, enabling real-time analytics, accurate reporting, and predictive modeling
Our data engineering expertise, innovative projects, and commitment to delivering tangible value ensure that businesses can unleash the true potential of their data, accelerate growth, and stay ahead in the dynamic and data-centric business world
- Skills
Real-time Data Processing: Knowledge of real-time data processing frameworks, stream processing technologies (e.g., Apache Kafka), and event-driven architectures to handle streaming data, enable real-time analytics, and build responsive data pipelines.
Data Quality and Governance: Understanding of data quality assessment techniques, data profiling, data cleansing, and data governance frameworks to ensure data accuracy, consistency, and compliance with regulations and industry standards.
Cloud Computing: Proficiency in cloud-based data engineering platforms, such as AWS, Azure, or Google Cloud, to design and deploy scalable and cost-effective data solutions, leveraging cloud storage, compute resources, and managed services.
Big Data Technologies: Familiarity with big data platforms and technologies, such as Hadoop, Spark, and NoSQL databases, for processing and analyzing large volumes of data, handling data velocity and variety, and building scalable data architectures.
Data Warehousing: Experience in designing and implementing data warehousing solutions, including schema design, indexing, partitioning, and optimization, to enable high-performance analytics and reporting.
Data Modeling: Knowledge of data modeling techniques and tools to design logical and physical data models that support efficient storage, retrieval, and analysis of data.
ETL: Proficiency in designing and implementing efficient ETL processes to extract data from source systems, transform it to the desired format, and load it into the target data repositories or data warehouses.
Data Integration: Expertise in integrating data from various sources and formats, including structured and unstructured data, databases, APIs, and file systems, ensuring seamless data flow and interoperability.
- Following are some example projects that we can build for our clients
Developing a data privacy compliance framework to ensure the protection of sensitive data and compliance with data privacy regulations (such as GDPR, CCPA, or HIPAA). This project involves implementing data anonymization techniques, encryption mechanisms, and access controls to safeguard personally identifiable information (PII) and sensitive data. The framework also includes data masking and tokenization techniques to protect data in non-production environments, as well as audit trails and data lineage tracking to demonstrate compliance with privacy regulations.
Creating end-to-end machine learning pipelines that encompass data preprocessing, feature engineering, model training, evaluation, and deployment, enabling companies to leverage machine learning models for predictive analytics and decision-making.
Building a scalable and cost-effective data lake architecture to store and process large volumes of structured and unstructured data, facilitating data exploration, analytics, and machine learning.
Implementing monitoring tools and techniques to track the performance and health of data pipelines, identifying bottlenecks, optimizing data processing workflows, and ensuring the timely and accurate delivery of data.
Building real-time data streaming and analytics solutions using technologies like Apache Kafka, Apache Flink, or AWS Kinesis. This project enables organizations to ingest, process, and analyze streaming data from various sources, facilitating real-time insights, monitoring, and decision-making.
Assisting organizations in migrating their data infrastructure to cloud platforms (such as AWS, Azure, or Google Cloud) and modernizing their data systems. This project involves designing and implementing cloud-native data architectures, leveraging managed services for data storage and processing, and enabling scalability, cost optimization, and agility in data management.
Developing a comprehensive data catalog and search platform that enables users to easily discover and access relevant data assets within the organization. This project involves building metadata repositories, implementing search functionalities, and establishing data classification and tagging mechanisms for efficient data discovery and collaboration.